

Under Review
Garment manipulation has attracted increasing attention due to its critical role in home-assistant robotics. However, the majority of existing garment manipulation works assume an initial state consisting of only one garment, while piled garments are far more common in real-world settings.
To bridge this gap, we propose a novel garment retrieval pipeline that can not only follow language instruction to execute safe and clean retrieval but also guarantee exactly one garment is retrieved per attempt, establishing a robust foundation for the execution of downstream tasks (e.g., folding, hanging, wearing). Our pipeline seamlessly integrates vision-language reasoning with visual affordance perception, fully leveraging the high-level reasoning and planning capabilities of VLMs alongside the generalization power of visual affordance for low-level actions.
To enhance the VLM's comprehensive awareness of each garment's state within a garment pile, we employ visual segmentation model (SAM2) to execute object segmentation on the garment pile for aiding VLM-based reasoning with sufficient visual cues. A mask fine-tuning mechanism is further integrated to address scenarios where the initial segmentation results are suboptimal.
In addition, a dual-arm cooperation framework is deployed to address cases involving large or long garments, as well as excessive garment sagging caused by incorrect grasping point determination, both of which are strenuous for a single arm to handle. The effectiveness of our pipeline are consistently demonstrated across diverse tasks and varying scenarios in both real-world and simulation environments.
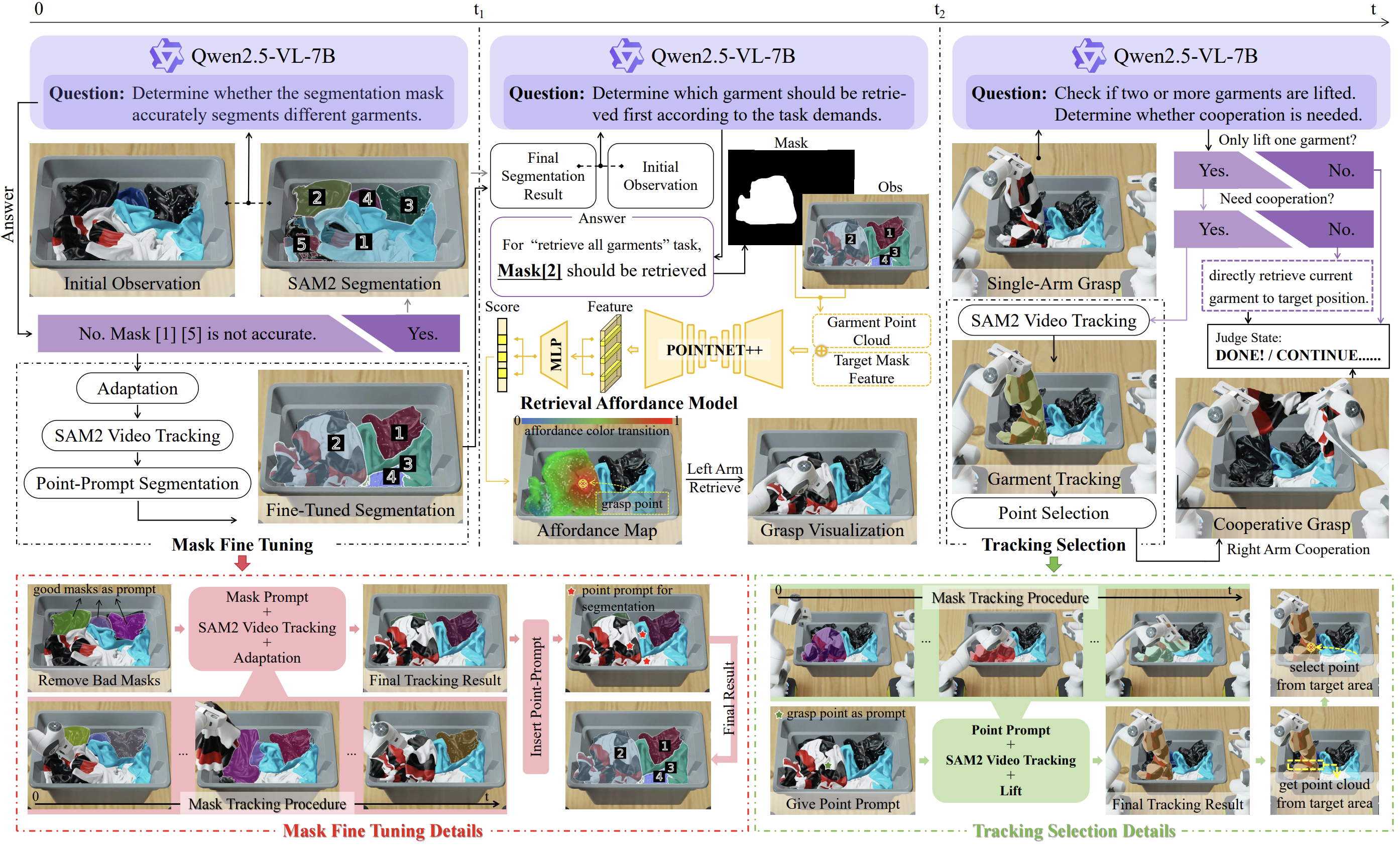
Given the initial observation, SAM2 segments the garment pile. Due to pile complexity, masks may be inaccurate, thus optionally triggering mask fine tuning procedure (Bottom-Left, red) based on VLM reasoning.
The finalized mask and observation are then passed to the VLM to select the target garment under task constraints. Treating the target mask as garment pile point-cloud feature, the Retrieval Affordance Model (RAM) predicts single-arm grasp points, which is used for single-arm retrieval. Then the post-grasp observation is requeried by the VLM to decide on dual-arm cooperation; if required, a tracking-selection module (Bottom-Right, green) produces cooperative grasp points to ensure successful retrieval.
What's more, if VLM detects the single-arm grasp of more than one garment, the current retrieval will be terminated.

Initial segmentation result (left-side images of each part) may be flawed: e.g., a mask covering multiple garments (mask 1 in blue part row 1, 2; mask 1 in orange part row 1), fragmented masks (mask 5 in orange part row 2; mask 4,6,7 in green part), or color confusion (mask 7 in cyan part covering two white garments). ✩ denotes the lift point for tuning. After fine tuning, the adjusted masks (right-side images of each part) are clearly more reasonable, with each mask generally corresponding to a single complete garment.

The color transition (blue → green → red) indicates an increasing affordance level. Beyond generalization across different garment types, the affordance further captures: garment geometry (row 1, center regions of garments are typically preferable.), subtle structures (row 4, garment wrinkle regions easier to grasp exhibit higher affordance level.), spatial relations (row 3 left, grasping left / right region of glove is equivalent, but the right side is preferable due to fewer garments, as well as tops side of garment in row 3 right; row 2, central regions far from closed boundaries are preferable for grasp safety.)

For sequential garment retrieval (rows 1 and 3), the VLM infers the most suitable garment to retrieve (e.g., topmost or with simpler entanglement) to maximize overall success. For specific garment retrieval (row 2), it inters to remove obstructing garments so that the target garment is quickly exposed and ready for retrieving.